
In meinem vorletztem Blogpost ging es um ein einfaches Beispiel für Neuronale Netze und Reinforcement Learning: Hello World ANN Projekt. Ich empfehle jedem mit dem einfachen Beispiel anzufangen.
Hier soll es nun um einen Roboter gehen der mit vier Servomotoren, etwas Lego, Kleber und Schrauben in einer Stunde zusammengebaut wurde. Er ist mit Sicherheit keine Schönheit und auch mein erster Roboter überhaupt. Davor hat mich die Thematik Roboter, egal in welcher Form, gar nicht interessiert, aber ich verstehe schon langsam die Faszination dahinter.
Hier ein Bild des schlauen Gefährten:

Außer der vier Servomotoren als Beine gibt es noch eine Ultraschallkapsel zur Entfernungsmessung und das STM32F407 Discovery-Board als Steuerzentrale, bekannt aus einigen meiner anderen Projekte. Die externen Kabel sind zur Stromversorgung und Programmierung (weiß) und ein UART-USB-Wandler (schwarz), um zu schauen, was der Robi gerade so treibt (Debug printf).
Jetzt hatte ich natürlich keine Ahnung davon wie man die Beine optimal ansteuert, um eine Vorwärtsbewegung zu programmieren. Programmieren wollte ich schon mal gar nicht. Ich wollte ein künstliches neuronales Netz mit der Aufgabe „beauftragen“. Zumal die Aufgabe gar nicht einfach ist, an welchem Tier ohne Kniegelenke und Fuß sollte man sich als aufmerksamer Mensch orientieren? Vorschläge gern in den Kommentaren…
Für die Beinbewegung musste ich erstmal einen Servo-Treiber schreiben, der auch eine Geschwindigkeitsbegrenzung der Bewegung erlaubt. Die Beine sollten also nicht so schnell wie möglich von einer Position zu anderen rauschen.Womöglich wäre sonst der ganze Roboter schon auseinander gefallen.
Nun ein paar Gedanken zum Modell mit KNN/ANN und Q-Learning:
- Um die Aufgabe durch Q-Learning lösen zu können, muss ein MDP modellierbar sein. Das heißt vereinfacht, nur Zustände keine Analogwerte als Ausgangswerte. So direkt kann das ANN die Motoren also nicht ansteuern.
- Die Anzahl der Möglichkeiten die das System annehmen kann, sollten nicht zu groß werden, sonst würde der Lernprozess viel zu lange dauern.
- Die Eingangswerte sollten die aktuellen Motorpositionen sein. Damit das ANN aber ein Gedächtnis bekommt müssen auch ältere Zustände als Input eingefügt werden. Dies könnte man zwar mit einem RNN geschickter lösen, aber dieses Netzwerk steht mit der FANN lib nicht zur Verfügung und lernt auch algorithmisch viel aufwändiger.
- Besteht die optimale Bewegung aus vier Grundschritten werden 4 * 3 Input-Neuronen nötig: Vier Motoren mit der aktuellen Position und zwei alte Positionen für jeden Motor.
- Die Output-Neuronen können keine anlogen Werte liefern. Da beim Q-Learning die beste Aktion maximiert wird(wer mag kann auch minimieren), stehen nur States am Ausgang des ANNs zur Verfügung. Daher sollte die Anzahl der Motorpositionen pro Motor limitiert werden.
- Sind am Ausgang drei Positionen pro Motor möglich, berechnen sich die möglichen Zustände der Eingänge wie folgt:
power(Zustände, Input-Neuronen) = power( 3, 12 ) = 531441 Möglichkeiten
Etwas viel um diese in annehmbarer Zeit halbwegs abdecken zu können. Jedoch gibt es sicher sehr viel ähnliche Bewegungen, die zum selben Ergebnis führen (symmetrische Bewegungen x-,y-Achse).
Nach diesem Gedankenspiel und natürlich einigen Stunden an Versuchen bin ich auf folgende ANN-Konfiguration gekommen: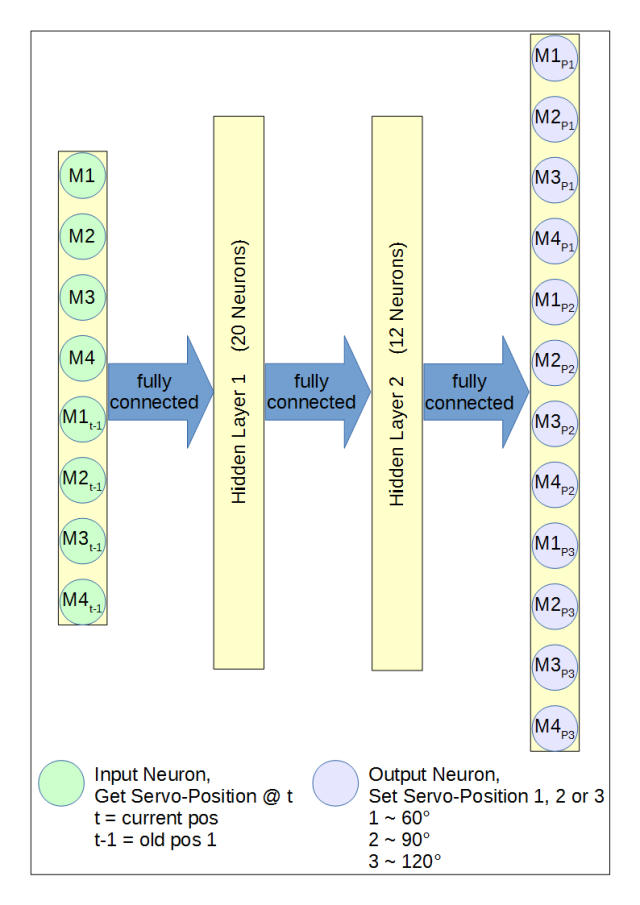
Der Agent vergibt die Rewards (maximiert eine gute Aktion), wie in nachfolgendem Bild dargestellt.
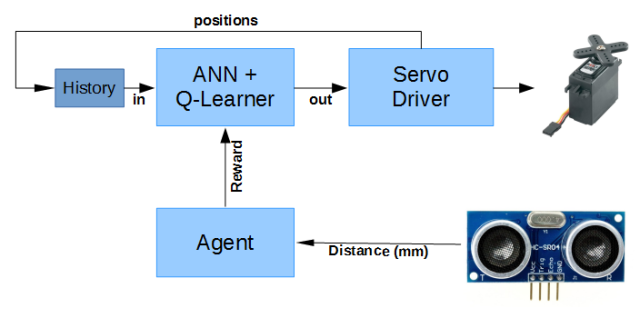
Für den Lernprozess habe ich einige Varianten aus den aktuellen Patenten und Papers der von google übernommenen Firma Deep Mind übernommen und getestet:
https://www.google.com/patents/US20150100530 -> Patent zum Q-Learning auf einer alten Kopie des ANNs
https://storage.googleapis.com/deepmind-data/assets/papers/DeepMindNature14236Paper.pdf -> ein paar Tipps und Tricks, wie Deep Mind die Netzwerke parametriert hat
Das Kopieren des ANNs (Patent) sorgt natürlich dafür, dass doppelter Speicher für die Gewichtungen und Verbindungen der Netze reserviert werden muss. Ein Netzwerk wird dabei nur trainiert und die Bibliothek FANN erzeugt hierfür noch einiges an Hilfsvariablen. So war recht schnell der Speicher voll (128 KB). Damit konnte ich das Kopieren des ANNs nur unzureichend testen. Jedoch habe ich letztendlich auch ohne das Vorgehen gute Ergebnisse erhalten. Die Begründung das Netz aller X Trainingszyklen zu kopieren, ist ein zu starker Lernanstieg bei guten Aktionen, der zu einer Art Schwingung und Instabilität führt, ähnlich wie es bei anderen Reglern passieren kann. Ich stell mir das Vorgehen/Patent wie ein Tiefpassfilter für ANNs vor.
Experience Replay habe ich diesmal intensive verwendet. Dazu habe ich 100 Trainingszyklen aufgezeichnet. Nachdem der Speicher voll war habe ich einfach das aktuelle Ereignis an eine zufällige Position des Speichers geschrieben, also einen alten Wert überschrieben. Danach wurden in jeder Iteration 20 zufällige Trainingszyklen ausgewählt, die Bereits vom Agent bewertet wurden. Mit dieser Minibatch wurde ab dem hundertstem Trainingszyklus trainiert. Der Unterschied ist, dass die Gewichtungen des Netzwerks erst nach dem Durchlauf einer kompletten Minibatch aktualisiert werden (eine Epoche). Dies verhindert ein Verändern der selben Gewichtungen in unterschiedliche Richtungen, da mehrere Daten als Referenz zur Verfügung stehen und sich dadurch bessere Strategien ergeben („der Blick fürs Ganze“).
Da die Minibatch natürlich nur Mini ausfällt, sollte man es mit der Lernrate nicht übertreiben, sonst wird die aktuelle Auswahl überbewertet. Die resultierenden Ausgänge sollten sehr selten -1.0 (min) oder +1.0 (max) sein und möglichst wenige Ausgänge sollten die selben Werte annehmen.
Eine falsche Lernrate führte zu folgendem, zugegeben recht witzigem, Ergebnis:
Die unterschiedlichen Bewegungsabläufe sind durch absichtlich hinzugefügten Ist-Winkel-Jitter der Servomotoren zu erklären. Die starke Änderung durch den leichten Winkel-Jitter ist mit Overfitting erklärbar.
Oder menschlicher ausgedrückt: Vorwärts ist er ein alter Mann mit Krückstock und Rückwärts ein Betrunkener der versucht Halt zu finden, indem er alle Gliedmaßen weiter auseinander streckt.
Es stellte sich während meiner Experimente heraus, dass die Ultraschallmessung den Abstand nicht immer korrekt wiedergab. Ein Tiefpassfilter erschien mir nicht ausreichend, da einige Werte zu stark abwichen. Ich nehme nun fünf Messungen pro abgeschlossene Bewegung und berechne den Median. Die Ergebnisse wurden damit deutlich besser, da weniger widersprüchliche Aktionen für Verwirrung stiften konnten.
Ein paar Dinge die nicht funktioniert haben oder nur einen sehr geringen Einfluss zeigten:
- Die Fehlerrückführung in das ANN sollte nicht durch adaptive Lernraten vorgenommen werden. Da eine kleine Lernrate durchaus Messfehler verzeiht und verhindert das die Ausgangs-Neuronen schnell bei ihrem Maximalwert sättigen. Mit FANN sollte unbedingt der BATCH-Algorithmus verwendet werden.
- Anfangs hatte ich Probleme mit der gerade beschriebenen Sättigung. Die Beine des Roboters haben sich nicht mehr bewegt. Um das zu verhindern habe ich zusätzliche Rewards für die Bewegung jedes Beines vergeben. Dies war jedoch nach der korrekten Einstellung nicht mehr nötig, da natürlich implizit eine Beinbewegung für einen positiven Reward nötig ist.
- Deep Mind meinte im Atari Paper bessere Ergebnisse erzielt zu haben, wenn der Reward bei -1,0 oder 1,0 abschnitten wird, da ja auch das Netzwerk keinen Output über dieser Größe zulässt. Ich kann das nicht bestätigen, jedoch war der Reward nicht so oft über diesem Wert.
- Weniger Lernzyklen als 300 brauchen nicht ausprobiert werden. Dazu ist die Anzahl der Möglichkeiten zu groß. Meist habe ich 700 genommen. Je nach Einstellung dauert eine Lernphase um die 12 Minuten.
- Mehr als ein alter Schritt (Bewegungs-History) ist nicht nötig, da auch bei größerer History der Roboter nur zwei verschiedene Bewegungen erlernt. Außerdem würde sonst die Eingangsmöglichkeiten schnell ansteigen. Dies erfordert mehr Trainingszyklen, um diese auch effektiv auszunutzen. Jedoch kann man dies Reduzierung erst sehen, wenn schon versucht wurde ein Netzwerk mit größerer History zu trainieren, jedoch nur zwei Bewegungen als effektiv angenommen wurden.
Wenn die passenden Parameter gefunden sind, dann könnte es so aussehen:
Der komplette Quellcode ist wie immer in meinem Github-Account zu finden:
https://github.com/Counterfeiter/Q-LearningRobot
Es ist nach jedem Parameterwechsel interessant zu sehen, was der Roboter diesmal anstellt und gelernt hat. Es ist schon erstaunlich, wie er sich das Laufen selbst beibringen kann. Ich habe mir nicht mal die Arbeit gemacht bei gegenüberliegenden Servos die Winkelposition zu invertieren. Da auf der einen Seite das Bein bei gleicher Ansteuerung vorn und auf der anderen Seite nach hinten gezogen wird. Das findet das Netz recht schnell selbst heraus.
Auch deuten die aktuelle veröffentlichten Untersuchungen und erteilten Patente darauf hin, dass man ganz dicht hinter der „neusten“ Forschung experimentiert. In welchen anderen Bereichen kann ein Hobby dies schon aufweisen? Vielleicht findet man durch ein paar Versuche selbst noch optimalere Ergebnisse…. spannend!
Ich hoffe auf viele weitere Roboter die aufbauend auf diesen Grundlagen und dem Quellcode das Licht der Hobbywelt erblicken. Lasst mich von eure eigenen Kreationen über die Comments wissen…

Pingback: Train Your Robot To Walk with a Neural Network | Hackaday
Pingback: 火車你機器人到走路與神經網路 - 何解
Pingback: Train Your Robot To Walk with a Neural Network – Boltron – Technogeek Marketplace
Pingback: Train Your Robot To Walk with a Neural Network – Hackaday | About Machine Learning
Pingback: Control robots using artificial neural networks – Ene mene mu …
Pingback: Simulation von Bewegungsabläufen | Electronic Stuff
Hello,
I try to implement an a2c to make a robot quadrupede walk, using 4 servos and 1 sonic just like you.
The programme is full browser with tf.js and a python Flask server.
However the model is not converging, and I have some doubt on how to drive 4 actions together (4 legs of my robots). how to set advantages of the actor.
Your code in C is pretty not clear for me.
Would you have time / interest to help me?
Alexandre from Lyon, France.
alexpanda9@hotmail.com
Hi Alex,
some points you should know:
– Servo positioning is without feedback, you should wait a bit until the move is done
– The ultra sonic sensor output should be filtered, I think I have median and mean filtering, because of the wobbling robot the sensor values are jumping a lot. Graph this values to see if it is a good reward signal.
– A2C could be used discrete like my q-learning implementation, so you need a neuron for every leg and possible servo position. But it could be also used with continues signals. Would be interesting to see this kind of solution but its out of scope to my blog post. Also this will drastically increase the possible state space.
best regards
Sebastian
Hello,
It is a very interesting project Sebastian.
Please could you share the hardware connections between the STM32F407 board, HC-SR04 and the servo motors?
Thanks in advance,
Best Regards,
Guillaume